[운영체제] Swapping
본 내용은 [Operating Systems : Three Easy Pieces] 및 부산대학교 안성용 교수님의 운영체제 수업을 참고하였습니다.
앞에서는 address space가 매우 작아서 모두 physical memory에 할당이 된다고 가정하였지만, 실제로는 address space의 크기도 크고 수많은 process가 실행되므로 physical memory 의 공간이 충분하지 않다.
따라서, 추가적인 레벨의 메모리 계층이 필요하다. (현대 운영체제는 hard disk가 그 역할을 하고 있음)

위의 그림은 memory hierarchy를 보여주고 있는데, 밑의 층이 위의 층의 "backing store" 역할을 한다.
즉, cache는 register의 backing store 역할을 하고 main memory는 cache의 backing store 역할을 한다. (직관적으로도 이해 가능)
How to Swap?
그렇다면 swap의 필요성을 알았으니 어떻게 swap을 하는지 알아볼 차례이다.
- Memory overlay 기법 : 예전에는 프로그래머가 직접 코드레벨에서 코드 또는 데이터의 일부를 메모리에 탑재하거나 제거했다. 따라서 OS의 도움은 필요없지만 매우 번거로우므로 더 이상 사용되지 않는다.
그 다음 process-level swapping과 page-level swapping이 존재하는데, 전자는 process 자체(해당 프로세스의 address space)를 필요하지 않은 시점에는 backing store로 보내고, 필요시에 다시 physical memory에 가져오는 방식이다. 후자는 process 단위가 아니라 page 단위로 backing store로 보내고(swap-out) 필요시에 다시 가져오는(swap-in) 방식이다.
multi-process 방식을 사용하는 만큼 효율적인 측면에서 page-level swapping이 더욱 유용하다고 할 수 있다.
Where to Swap?
- swap space
디스크에 page들을 저장할 수 있는 일정 공간을 확보하는데, 이 공간을 swap space라고 한다. memory의 page 를 읽어서 이 swap space 에 쓰고(swap-out), 여기서 page를 읽어 메모리에 탑재한다(swap-in).
일단, swap space의 입출력 단위는 페이지라고 가정하자. 그리고 운영체제는 swap space에 있는 모든 페이지들의 디스크 주소를 기억하고 있어야 한다.
이 swap space의 크기는 시스템이 사용할 수 있는 memory page의 최대 수를 결정하기 때문에 매우 중요하다.

위의 예에서 Process 0, 1, 2, 3이 존재하는데, Proc3 같은 경우는 물리메모리에 페이지가 하나도 올라가 있지 않으므로 현재 실행중이 아닌 것으로 보이고, 다른 process 들은 현재 필요한 페이지 이외의 페이지들을 swap out 시켜놓은 것을 알 수 있다.
위의 예에서 Proc 0 을 보면, Proc 0의 VPN 0 을 뺀 나머지 1, 2번은 현재 스왑공간에 탑재되어 있다. 실제로 Physical memory에 탑재되어 있지 않지만, Process는 자신이 Physical memory에 자신의 Page들이 모두 탑재되어 있다고 환상을 가지게 된다(OS가 그 페이지들을 필요시점에 Physical memory로 swap-in 해주기 때문). 따라서 위에서 swap space의 크기가 시스템이 사용할 수 있는 memory page의 최대 개수를 결정한다고 한 것이 이제 이해가 갈 것이다.
그리고 Process는 처음 memory에 탑재될 때, 모든 VPN들을 Physical memory에 탑재할 수 없다면 가장 먼저 code나 data page들을 탑재한다.(그래야만 해당 명령어를 실행하고 데이터에 접근할 수 있기 때문)
Present Bit
이전에 하드웨어 기반의 TLB를 사용하는 시스템을 가정하여 생각해보자.
메모리가 참조될 때, 프로세스가 address space 의 메모리참조를 하고, 하드웨어는 가상주소를 물리주소로 변환하는 과정을 거친다. 먼저 하드웨어는 TLB에서 해당 정보가 있는지 검사한다.(있으면 hit) 없을 경우(TLB miss) 하드웨어는 페이지 테이블의 베이스 레지스터를 이용해 (물론 페이지 디렉터리 접근 과정이 앞에 있음) 원하는 PTE를 추출한다. 여기서 이제 Present Bit의 역할이 추가된다. 만약, 해당 page가 현재 memory에 탑재되어 있지 않다면, (valid 하더라도 디스크로 swap-out 되어있다면 현재 메인메모리에는 없음) 이 경우에는 present bit을 0으로 해주는 것이다. 따라서 이렇게 물리 메모리에 존재하지 않는 페이지를 접근하면 이를 page fault 라고 한다.
Page fault가 발생하면, 이를 처리하기 위해 운영체제로 제어권이 넘어가고, 페이지 폴트 핸들러(Page fault handler)가 실행된다.
Page Fault Control Flow
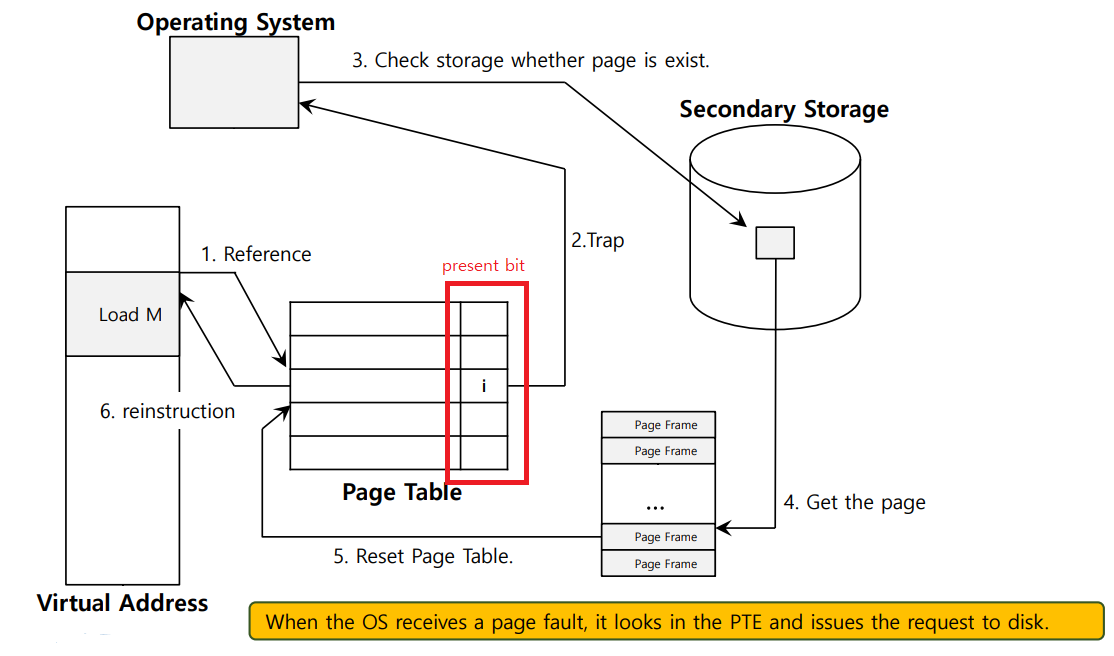
위의 그림은 page fault의 간략한 control flow를 나타낸 것이다.
빨간 부분에서 present bit에서 0 인 상황에 page fault가 발생하면 trap을 발생시키고, 운영체제는 secondary storage에서 page를 찾아 물리 메모리에 탑재를 해주는 것이다.
다음은 간략한 pseudo code를 통해 page fault control flow를 알아보자.


다음은 Software에서 page fault를 처리하는 pseudo code이다.

하지만 위의 방식들에는 문제가 있다. 위의 pseudo code에서는 메모리가 꽉 찰 때까지 기다리게 되는데, 따라서 물리 메모리가 꽉 찬 이후에는 모든 접근마다 page-fault가 일어나게 되므로 큰 overhead와 성능적인 문제가 생기게 된다.
따라서 이는 좀 비현실적이고, 실제로는 운영체제가 항상 어느 정도의 여유 메모리 공간을 확보해둔다.
대부분의 OS는 최댓값(high watermark, HW)과 최솟값(low watermark, LW)를 설정해서 교체 알고리즘에 활용하는데, 메모리의 여유 공간이 LW보다 작아지면 여유 공간 확보를 담당하는 쓰레드가 실행되어 여유 공간이 HW에 이를 때까지 페이지를 제거한다. 이 쓰레드를 일반적으로 swap daemon 또는 page daemon이라고 부른다.
What if Memory Is Full?
만약 메모리에 여유 공간이 없으면 어떻게 해야 할까?
운영체제는 new page들을 위한 공간을 만들어야 한다.
이 과정에서 교체되는 기존의 page들을 어떻게 정할 것인가 하는 문제가 생긴다.
이를 선택하는 것을 page-replacement policy라고 한다.
What to Swap?

OS는 memory에 여유 공간이 부족할 때 위와 같은 방식으로 우선순위를 둔다.
주로 drop을 시키는 page들은 언제든지 다시 보조메모리에서 다시 가져올 수 있는 경우가 많다.
그렇다면, replacement policy를 어떻게 설정하느냐에 관한 문제를 생각해 볼 수 있다.
이때 나오는 개념이 Cache Management이다.
Cache Management
앞에서 우리는 TLB에서도 그렇고 cache의 개념에 대해서 배웠었다.
이 메인메모리도 cache처럼 최대한 많은 hit가 나서 replacement의 overhead가 최대한 적기를 기대할 수 있으므로 우리는 메인메모리를 하나의 cache처럼 생각할 수 있다.
Cache의 hits 와 misses를 계산하는 하나의 척도가 있는데 이를 AMAT(average memory access time)이라고 한다.

복잡해보이지만 사실 단순한 식이다. 예를 들어 해당 cache의 hit율이 0.7이고 그 cache에 hit 했을 경우 1ns의 시간이 소요되고, miss 했을 경우 backing store에 접근하는 시간이 10ns 라고 하면 AMAT는 0.7*1 + 0.3*10 = 3.7ns 이렇게 계산하는 것이다.
The Optimal Replacement Policy
가장 먼 미래에 접근이 될 page들을 replace하는 policy 인데, 이는 가장 적은 cache miss 가 나게 해준다.
가장 optimal 하고 좋은 policy이지만 현실적으로 생각해보면 우리는 미래를 내다볼 수 없기 때문에 이 policy는 다른 policy들의 성능 비교를 위한 "지표" 로만 사용한다.
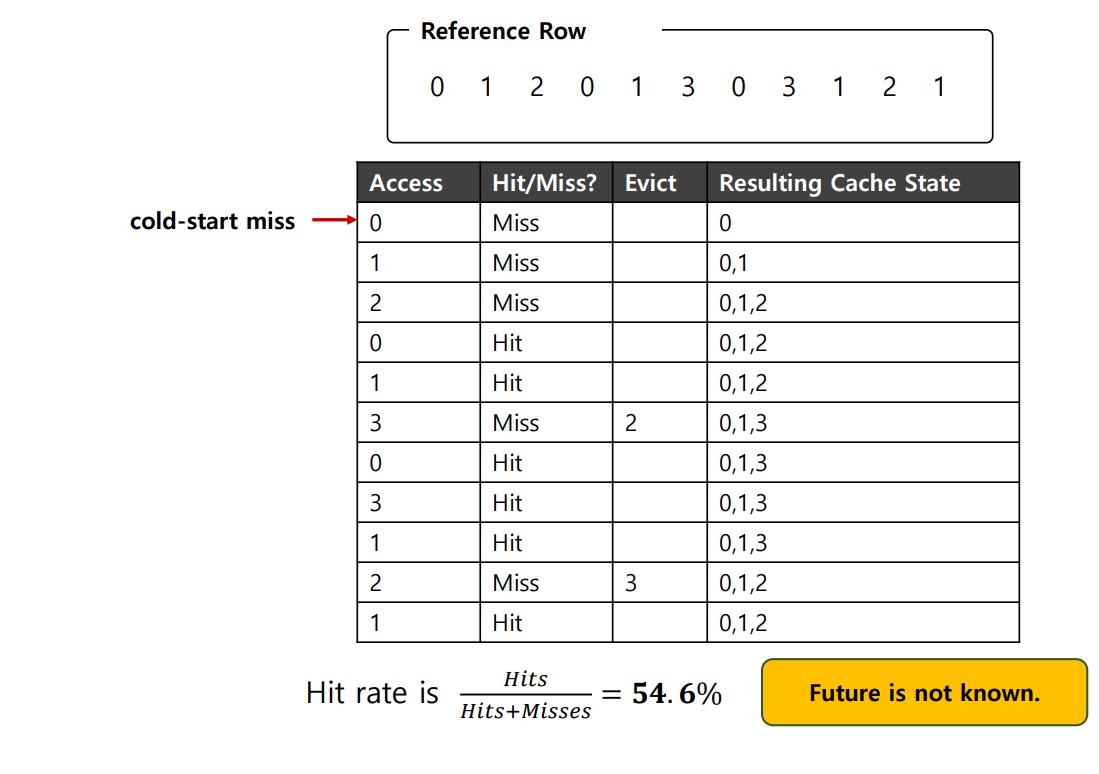
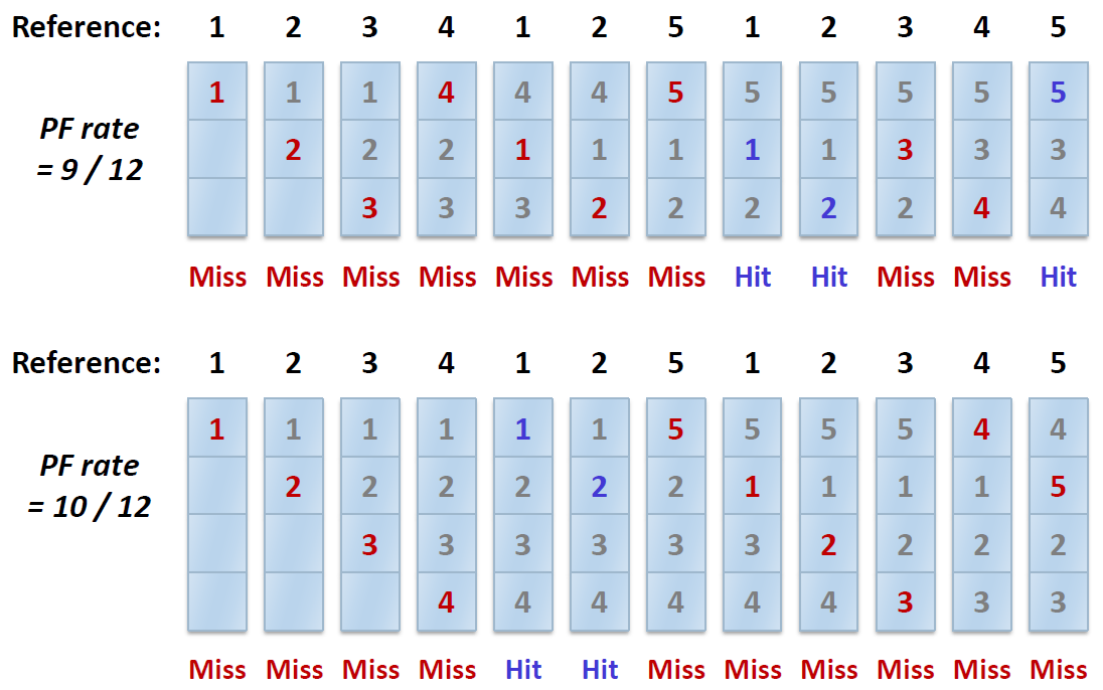
위의 optimal policy가 어떻게 진행되는지 한번 살펴보자.
전체 0,1,2,3의 4개의 page가 있다고 가정해보면, 처음 0,1,2의 miss는 cold-start miss일 수 밖에 없다.
그리고 3을 접근하는 경우를 보면, 0,1,2 중 2를 가장 먼 미래에 접근하므로 2를 교체하고, 밑의 2를 접근하는 경우(miss) 1을 제외한 0과 3 은 미래를 알 수 없으므로 이 상황에서는 가장 먼 미래에 접근하는 page가 되므로 둘 중 아무 page나 (여기서는 3을 선택) 교체한 것이 된다.
A Simple Policy : FIFO
페이지들은 system에 들어오면 그냥 순차적으로 queue에 들어오게 되고, replacement가 발생하면 queue의 가장 앞에 있는 page가 가장 먼저 evict 된다. (First In First Out)
이는 구현하기 매우 간단하고 쉽지만, 어떤 특정한 page들의 중요도나 접근빈도를 고려할 수 없으므로 똑똑한(?) policy라고 보기는 어렵다.
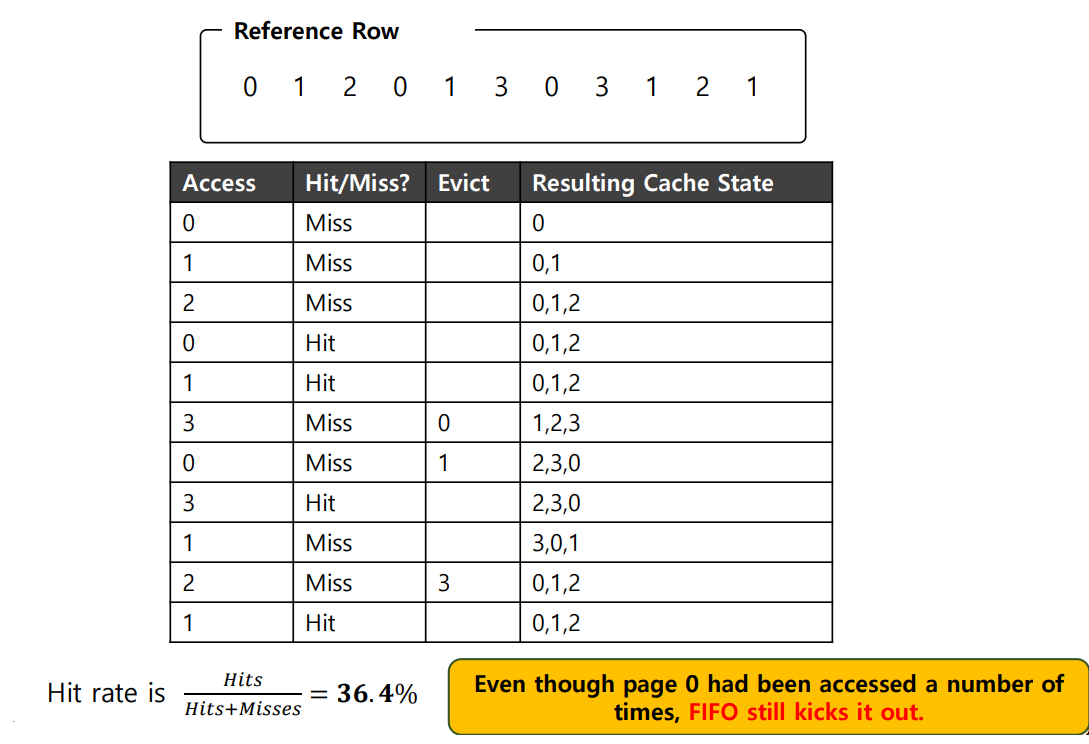
- BELADY'S ANOMALY
상식적으로 cache의 크기가 커지면 hit ratio 가 당연히 비례해서 커질 것이라고 기대하지만, 실제로는 FIFO policy에서는 더욱 나빠진다는 현상이다.
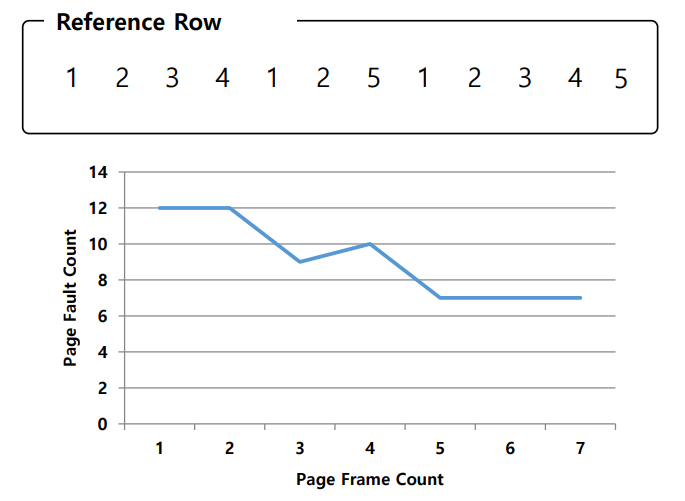
Another Simple Policy : Random
그냥 말 그대로 random 하게 evict 할 page를 고르는 것이다.
무식해 보이지만, 때때로 random한 경우가 optimal 만큼 좋은 성능을 보일 때도 있다.
하지만 현실적으로 좋은 policy 라고 보기 어렵다.
Using History
Optimal policy 같은 경우 미래를 내다볼 수 있다는 가정을 했었다.
미래를 내다본다, 즉 미래를 예측할 때 우리는 과거에 집중하기 마련이다.
따라서 여기서도 history를 기반으로 하는 policy가 등장한다.
Using History : LRU (Least Recently Used)
말 그대로 가장 오래 전에 접근된 page를 evict하는 것이다.
이전에 TLB에서 봤던 개념이랑 같은 개념이다.(locality 이용)
또한, "stack" 알고리즘으로, Belady's anomaly현상으로부터 자유롭다.
다만, 더 구현하기가 어렵고, page access의 빈도 등을 고려하지 않는다는 점에서 한계가 존재한다.
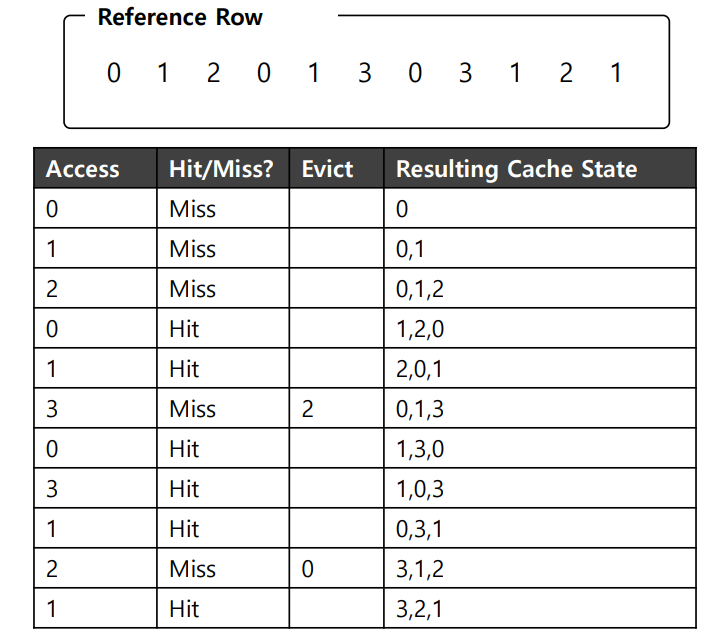
Stack algorithm을 사용했으므로 Belady's anomaly에서 자유롭다고 했는데 그 이유가 무엇일까?
아래의 그림을 보자.
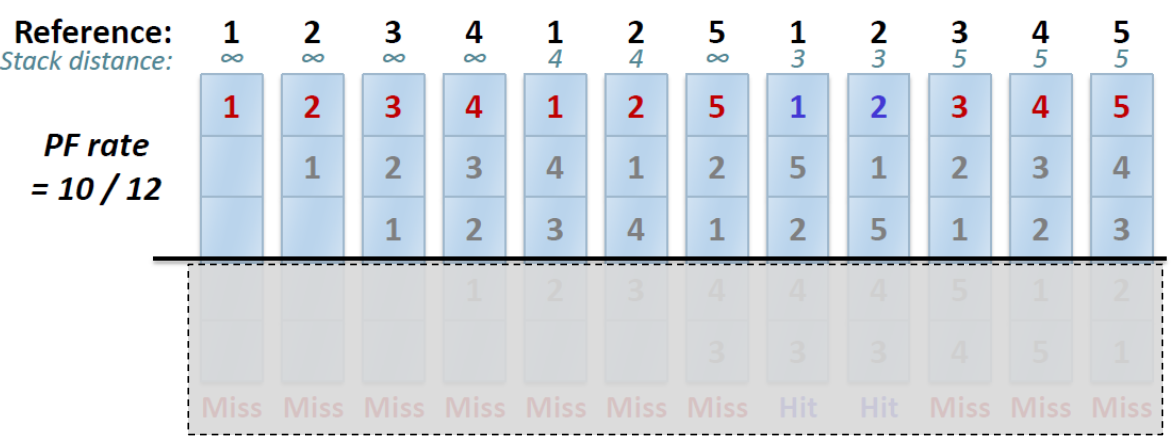
cache의 용량이 커지면 커질수록 이 policy에서는 성능이 좋아질 수 밖에 없는 이유는 stack algorithm이므로 더 용량이 적었을 때의 경우의 수가 "반드시" 더 큰 용량의 경우의 수에 포함되기 때문이다.
이제 Workload의 유형에 따라 policy들을 평가해보자.
Workload Ex : The No-Locality Workload

만약 locality가 존재하지 않는다면 locality에 기반을 둔 LRU 또한 제 기능을 전혀 하지 못하므로 그저 Cache size에 비례하며 hit ratio가 올라간다.
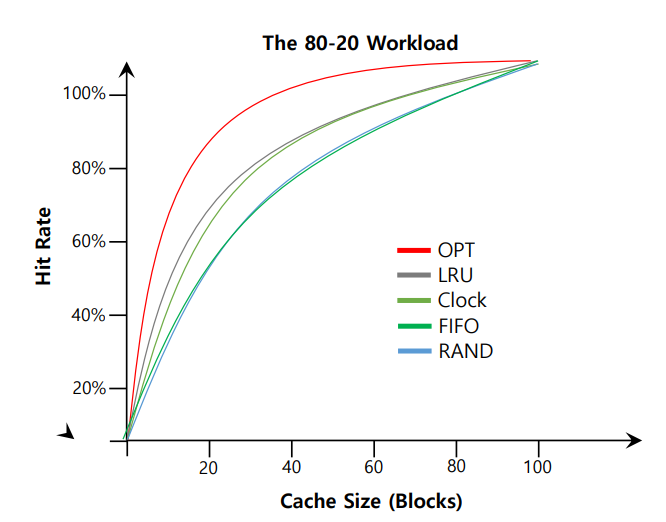
Workload Ex : The 80-20 Workload
이 수치는 자연의 섭리와도 가까운 수치라고 하는데, 80%의 reference가 20%의 page에서 일어난다는 경우이다.
따라서 자연스럽게 나머지 20%의 reference가 80%의 page에서 일어나게 된다.
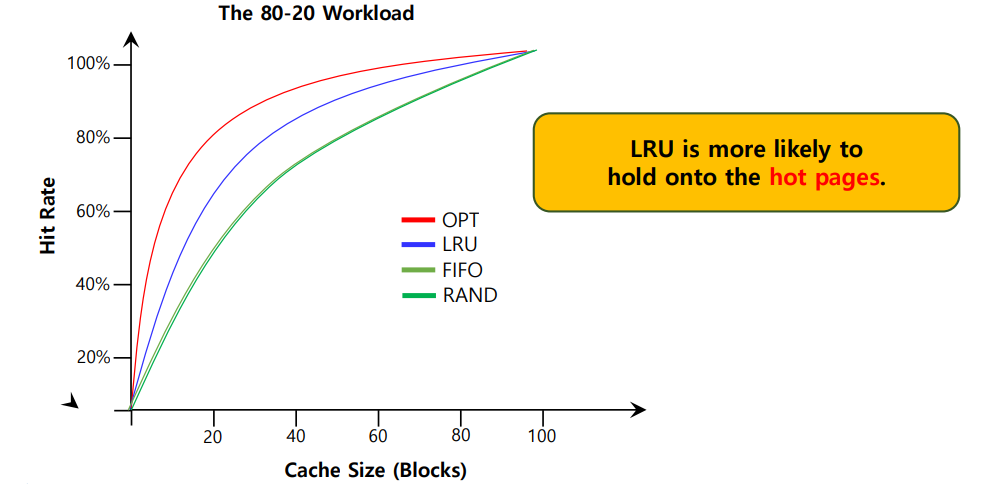
인기가 많은 page일수록 접근을 더 하게 될 것이므로 evict 되지 않고 계속 memory 에 존재할 것이다.
따라서 hit ratio가 LRU에서 우수한 것을 알 수 있다.
Workload Ex : The Looping Sequential
만약 50개의 페이지가 있고, 페이지 0부터 시작에서 1, 2, ..., 49까지 차례대로 접근한다고 가정해보자.
그럼 다음과 같은 결과가 나올 것이다.
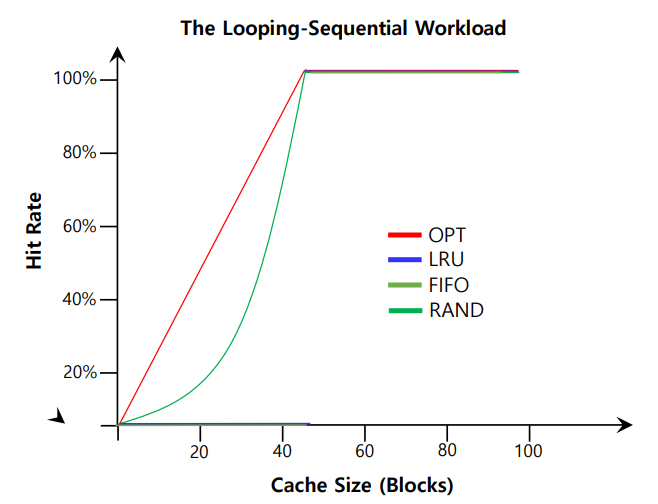
LRU와 FIFO모두 cache에 없던 page를 접근하게 되므로 계속 miss가 나게 되고, cache의 size가 50이 넘어가게 되면 그때부터는 100%의 hit rate를 보여준다.
이 경우에는 웃기게도 random 방식이 그나마 나은 성능을 보인다.
그렇다면 이 Historical Algorithm들을 어떻게 구현할 수 있을까?
계쏙해서 가장 최근에 사용한 page를 추적하기 위해서는 시스템이 계속해서 모든 memory reference마다 계산을 해주어야 한다. 따라서 hardward의 도움을 조금 받게 된다.
Approximating LRU
LRU 정책에 가까운 구현은 "가능"하다. 이 개념에는 use bit 이라고 하는 약간의 하드웨어의 지원이 필요한데, 시스템의 각 페이지마다 하나의 use bit가 존재한다.
페이지가 참조될 때마다 하드웨어에 의해서 use bit가 1로 설정이 된다. 한번 1로 설정이 되면 하드웨어는 이 use bit을 0으로 다시 설정하지 않는다.(운영체제에 의해서 필요에 따라 0으로 설정될 것)
과연 이 use bit을 이용해서 어떻게 LRU에 근사한 Policy를 구현할 수 있을까?
이 때, clock algorithm 이라는 개념이 등장한다.

시계 바늘이 돌듯이 이 clock hand가 특정 페이지를 가리킨다고 가정해보면, 가리키는 그 특정페이지의 use bit이 0이면 evict 하고 1이면 0으로 설정해준 후 다음 page를 가리키게 된다.
clock algorithm을 사용하게 되면 LRU에 근사한 성능을 기대할 수 있다.
Considering Dirty Pages
만약 어떤 page가 수정이 되면 dirty bit(aka modified bit)를 이용해서 수정 여부를 알 수 있게한다.
만약 page가 수정이 되지 않았다면 eviction은 그냥 이루어지지만, 수정이 되었다면 이는 반드시 evict 되기 전에 disk에 다시 쓰여져야 한다.
//문제제기 및 피드백 언제든지 감사히 받겠습니다.