[운영체제] File System Implementation
본 내용은 [Operating Systems : Three Easy Pieces] 및 부산대학교 안성용 교수님의 운영체제 수업을 참고하였습니다.
파일 시스템을 구현하려면 어떻게 해야할까.
VSFS(Very Simple File System)이라는 가상의 파일 시스템을 예로 들어 이해해보자.
VSFS
VSFS라는 이 가상의 파일 시스템의 특징을 먼저 살펴보자면,
- Disk를 블록 단위로 나눔(한 블록당 4KB)
- 블록의 사이즈는 sector size의 배수
- 대부분의 disk block 들은 user data를 저장하기 위해 사용됨
- 아주 작은 부분만 file system의 metadata를 저장하기 위해 사용됨

또, inode를 어떻게 저장할지도 고려를 해야한다.
각각의 inode는 file의 metadata를 가지고 있고, 크기가 고정되어 있다.
만약 한 inode당 256B의 크기를 가진다고 하면 4KB(VSFS에서 한 블록의 크기 가정)에는 16개의 inode가 저장될 수 있다.

위의 경우에는 5개의 블록을 아이노드 테이블로 잡았으므로 총 16 * 5 = 80개의 inode를 저장할 수 있다.
그 다음은, Bitmap에 대해서 알아보자.

Inode bitmap과 Data bitmap이 있는데, 각각의 bit는 상응하는 block 또는 inode가 free(0)한지 아니면 사용중(1)인지 나타낸다.
하나의 bitmap block은 32K의 블락 또는 inode의 상태를 표현할 수 있다.
(한 블록당 크기가 4KB 였으므로 4K * 1 Byte = 4K * 8 bit = 32K bit)
다음은 마지막으로 Superblock이다.

Superblock은 해당 file system의 metadata를 가지고 있다.
- File system type
- Block size
- Total number of blocks
- Number of inodes
- Number of data / inode bitmap blocks 등등..
따라서 file system을 마운팅할 때 가장 먼저 OS는 그 file system의 superblock을 먼저 읽어서 여러 정보를 초기화하는데 사용한다.
기본적인 파일 시스템의 구조를 살펴보았는데, 그렇다면 어떻게 파일을 disk block 에 mapping해줄 것인지 의문이 든다.
근데 다행히도 address space를 physical memory에 mapping해주는 과정과 유사해서 쉽게 이해할 수 있다.
할당하는 방법들을 하나하나 살펴보자.
Contiguous Allocation

이 경우에는 Metadata가 <starting block #, length> 만 가지고 있으면 된다.
보통 CD-ROM에 많이 쓰이는데 그 이유는 이와 같은 방식은 지우고 다시 쓰는 과정에서 external fragmentation이 쉽게 발생하는데 CD-ROM의 경우는 한번 write하면 잘 update 않기 때문이다.
위와 같은 방식은 파일의 크기가 커질 때 옮기지 않는 한 파일의 크기를 키우기가 어렵다.
하지만 sequential 한 access의 경우에 매우 좋은성능을 보이고 random access를 할 때에도 간단한 계산만으로 수행할 수 있다.
Linked Allocation

고정된 크기의 block으로 이루어진 linked-list로 파일을 구성한다.
이 경우 metadata는 <starting block #> 만 가지고 있으면 된다.
각각의 block들은 다음 순서의 block의 주소를 가지고 있다. 따라서 블록마다 이 pointer를 위한 공간을 낭비하게 된다.
그리고 하나라도 데이터 손실이 일어나서 포인터의 연결이 끊어지게 되면 그 뒤를 찾을 수 없게 되므로 치명적이다.
다만, 외부단편화가 없고 파일의 크기가 쉽게 변경이 된다는 장점이 있다.
File Allocation Table (FAT)
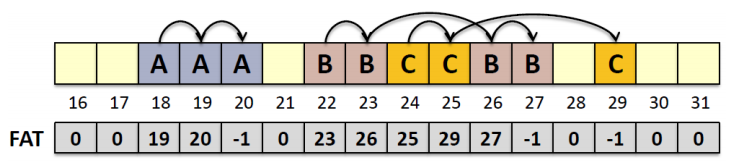
위의 연결리스트 방식을 그대로 사용하긴 하지만 여기서 참조를 위한 테이블을 추가적으로 사용하여 disk를 seek하는 시간을 아낄 수 있다.
이 FAT는 main memory에 캐시되어 있으며 이 경우 metadata는 <starting block #> + FAT 로 구성되어 있다.
-1의 경우 해당 파일의 끝을 나타낸다.(End Of File)
Index Allocation
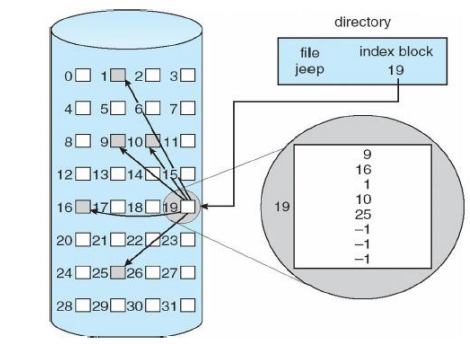
이 경우 그림처럼 파일의 data block의 포인터를 가지고 있다.
따라서 metadata는 block pointer들의 array이다.
외부 단편화가 없고 파일이 쉽게 grow 할 수 있다.(다만 max file size 있음)
이런 경우 sequential access의 performance는 data block 들이 어떻게 놓여있는지에 따라 다르고, 모든 data block들에 대한 pointer와 현재 파일의 크기 이상에 대한 포인터(-1)도 갖게되므로 metadata 에 엄청난 overhead가 있다.
Multi-level Indexing
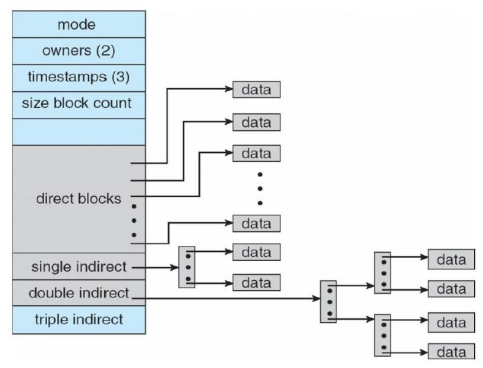
위의 Index allocation의 변형이다.
동적으로 data block에 대한 pointer를 할당하며, 적은 수의 direct pointers, 그리고 나머지 indirect pointer들을 갖게 된다.
이 경우 위와 반대로 불필요한 pointer들에 대한 공간을 낭비하지 않으며, indirect pointer를 접근하기 위해 indirect block을 읽어야한다. 이 때 추가적으로 disk reading을 해야하므로 주로 indirect block들은 main memory에 캐쉬되어 있다.

위 그림의 경우 12개의 direct pointer가 있고 하나의 indirect block안에 1024개의 indirect pointer가 있는 것을 알 수 있다.
따라서 이 inode의 파일은 (12 + 1024)*4KB = 4144KB이다.
Extent-based Allocation
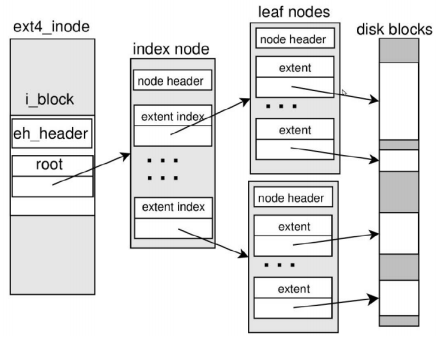
파일의 여러 contiguous한 공간들을 할당하고 이를 muti-level tree 구조로 관리한다.
각각의 leaf node는 <starting block #, extent size> 를 갖고 있으며 contiguous allocation 의 단점을 줄이고 장점은 최대한 유지한 방법이라고 할 수 있다. 따라서 여전히 좋은 sequential access performance를 보이고 metadata에 대한 overhead가 상대적으로 적다.
Directory Organization
Directory는 special 한 file로 directory의 entry들을 가지고 있다.
Inode에서 directory임을 구별하기 위해서 특정구간 bit표현을 다르게 한다.
VSFS의 경우, directory는 <file name, inode number>의 선형 리스트로 이루어져있다.
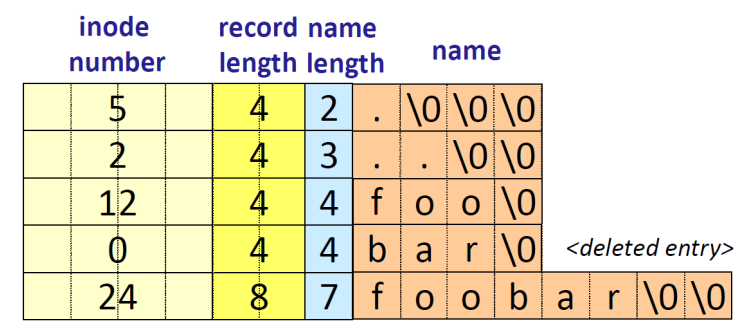
위의 그림에서 해당 디렉터리를 /dir라고 해보자.
현재 dir 라는 디렉터리 하위에는 foo, bar, foobar라는 파일이 있고 상위 디렉터리 ../ 그리고 자신 ./ 가 있다.
따라서 /dir 의 inode number는 5, root directory의 inode number 는 2임을 알 수 있다.
이제 파일을 읽고 쓰는 과정을 하나하나 뜯어보자.
세세한 과정을 이해할 줄 알아야한다.
Reading a File
먼저 open("/foo/bar", O_RDONLY) 를 issue 한다고 했을 때를 예로 들어보자.
우리는 원하는 inode가 어디 위치해 있는지 찾기 위해 pathname을 따라가봐야한다.
먼저 / (root) 부터 시작하므로 (보통 root는 unix에서 inode number 2임) 파일 시스템은 inode number 2를 포함하는 block을 읽는다. 그 후 root directory의 metadata중 datablock을 가리키는 포인터를 찾고 여러 directory data block 들을 읽어가면서 foo 라는 directory를 찾아낸다. 또 다시 위의 과정을 통해 원하는 inode ("bar")를 찾아낸다. 그 후 권한을 체크하고 file descriptor를 해당 process 에 할당해주고 user에게 반환한다.
그 다음 해당 파일을 읽기 위해 read()를 issue 하는데 파일이 시작하는 첫번째 data block을 찾기 위해 파일의 inode를 참고한다. 그리고 새로운 access time을 inode에 update 해주고 다음에 읽기 작업을 수행할 대 이전에 읽었던 마지막 위치부터 읽도록 해주기 위해 해당 file descriptor에 대한 offset을 open file table에서 갱신한다.
파일을 닫을 때는 file descriptor는 반드시 deallocate해준다. 현재로서는 그게 끝이다. Read에서는 특별한 disk I/O가 필요없다.
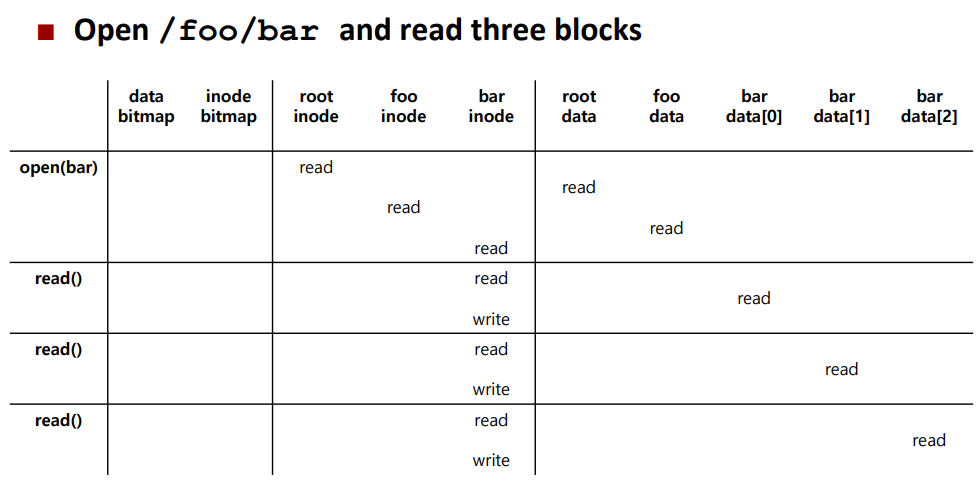
위의 그림은 /foo/bar를 열고 세 개의 block을 읽을 때 일어나는 일을 시간에 따라 정리한 것이다.
Writing a File
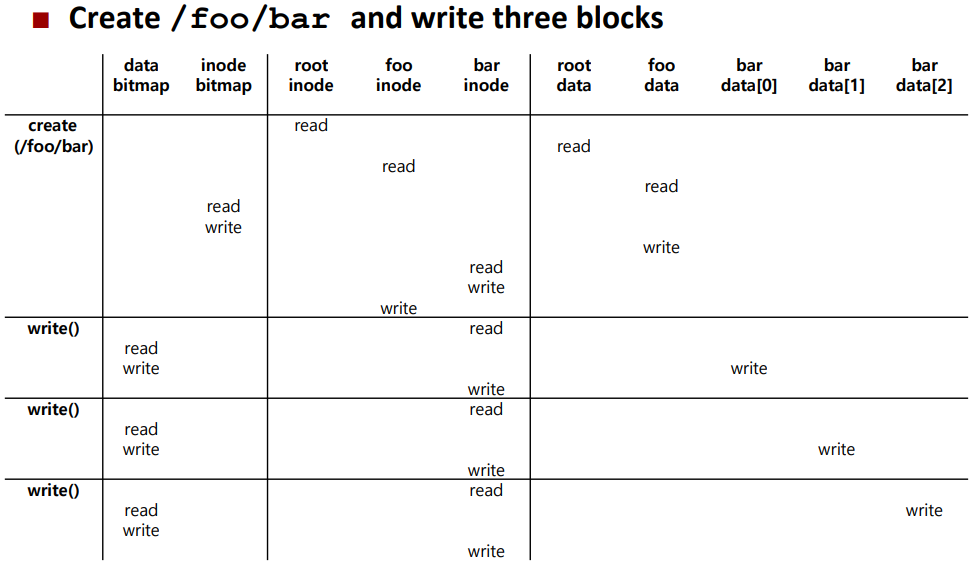
파일의 쓰기는 조금 더 복잡하다.
먼저, 앞에서 했던 것처럼 해당 파일을 연다.
그리고 write()를 issue 해서 새로운 내용으로 파일을 갱신하고, 파일을 닫는다.
read와는 다르게 write는 블럭 할당을 필요로 할 수도 있다.(기존 블럭의 내용이 update 되는 것이 아니라 추가적인 내용을 기록하다면)
새로운 파일을 쓸 때는 각 write는 데이터를 디스크에 기록해야 할 뿐만 아니라 파일에 어느 블럭을 할당할지를 결정해야 하고, 그에 따른 다른 자료 구조들을 갱신해야 한다.(data bitmap, inode, ...)
따라서 파일에 대한 쓰기 요청은 논리적으로 5번의 I/O를 생성한다.
- 한번은 data bitmap을 읽기 위해서(free data block 찾기 위해서)
- 한번은 data bitmap을 쓰기 위해서(새로운 상태를 disk에 반영하기 위해)
- 두 번은 해당 파일의 inode를 읽고 또 쓰기 위해서
- 마지막 한 번은 실질적인 data block을 쓰기 위해서이다.
//문제제기 및 피드백 언제든지 감사히 받겠습니다.