![[ML] 선형회귀(Linear Regression)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FK3GQz%2FbtrAIPcQp5v%2FnO6sDa4uZGcoFYD2PNbVG0%2Fimg.png)
본 내용은 ML GDE 박해선 님이 쓰신 [Do it 딥러닝 입문]을 참고하였습니다.
선형회귀를 많이 접해보았고 원리도 익숙하지만 이 Do it 책은 모델을 직접 코딩해보고 그 원리를 익힐 수 있어 되게 도움이 많이 될 거라 생각했다.
먼저 선형회귀란 어떠한 데이터가 주어졌을 때, 그 데이터를 가장 잘 나타내는 하나의 선형식을 모델링하는 것이다.
이때, 선형 모델을 모델링하고자 한다면 이 데이터와 타겟 간의 선형관계가 있다는 사실을 유추해내거나 가정을 하고 하는 것이다. 물론 데이터와 타겟 사이에는 선형적인 관계가 없을 수도 있는 것이다.
또한 선형회귀는 supervised learning의 일종으로 데이터에 대한 타겟(target)이 주어진다.
이번에 사용할 데이터는 사이킷런의 당뇨병 환자 데이터다.
데이터 준비
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()sklearn.datasets에서 load_diabetes를 import하고 diabetes 변수에 데이터를 담는다.
print(diabetes.data.shape, diabetes.target.shape)
// (442, 10) (442,)diabetes.data와 diabetes.target의 shape을 살펴보니 데이터는 442행 10열 즉 10개의 특성을 가진 442개의 데이터가 있는 것이고, 타겟은 442개의 단일 값만을 가진다.
즉 [특성1의 값, 2의 값, 3의 값, 4의 값, 5의 값, 6의 값, 7의 값, 8의 값, 9의 값, 10의 값]을 가지는 데이터가 442개 있고, 각 데이터마다 정답값 즉 target이 하나씩 존재한다는 것이다.
plt.scatter(diabetes.data[:,2], diabetes.target)
x축은 diabetes.data의 3번째 특성, y는 target으로 잡아서 산점도를 그려보니 꽤나 선형의 관계를 가진다고 유추할 수 있다.
x = diabetes.data[:, 2]
y = diabetes.target계속 3번째 특성과 target을 다 일일이 치기는 번거롭기 때문에 각각 x, y 에 담아준다.
경사 하강법(Gradient descent)
과연 위에서 보여주었던 산점도를 가장 잘 나타내는 직선은 무엇일까.
직관적으로 보라색 선이 산점도를 가장 잘 나타낸다는 사실은 우리도 알지만, 우리는 컴퓨터에게 이 직선을 찾게 해야한다. 이때 사용되는 것이 경사 하강법이다.
경사하강법은 이 선형 모델이 데이터를 가장 잘 표현하도록 gradient(변화율)을 이용해 모델을 조금씩 반복적으로 최적화해나가는 알고리즘이다.
y_hat 이란 선형모델을 통해 예측한 값이라는 뜻이다. 즉 우변의 wx+b 라는 모델에 x를 넣었을 때의 예측값을 의미한다.
손실 함수와 경사 하강법
손실함수는 실제 데이터의 target 값(y)에서 예측값(y_hat)를 뺀 값을 의미한다.
보통 제곱 오차(Squared Error)는 RSS(Residual Sum of Squares)라고 불리기도 한다.

손실함수는 그냥 식 그대로 실제 데이터의 타깃 y와 모델의 예측값인 y_hat의 차이의 제곱이다.
즉 데이터를 가장 잘 나타내는 모델을 만들기 위해서는 이 손실함수의 값이 최대한 작아야 한다.
실제로 y는 주어져있는 값이고 우리는 y_hat 즉 wx + b 의 값을 바꿈으로써 SE값에 변화를 줄 수 있다.(w, b를 바꿔줌)
이 때, 각각 w와 b에 대하여 SE를 편미분해준다.
다만, 이 글에서는 식의 간소화를 위해서 SE = 1/2(y-y_hat)^2 으로 정의하도록 한다.(손실함수의 정의는 데이터와 사용자의 편의에 따라 달리 할 수 있음)
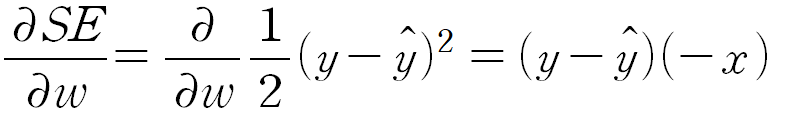
b에 대해 편미분을 해주면 아래와 같다.
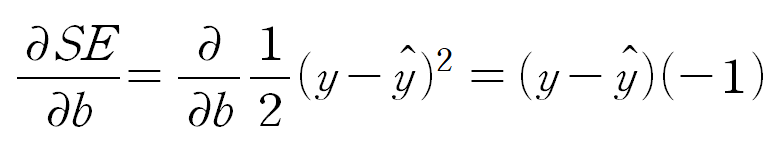
즉 이를 코드로 표현하면 다음과 같다.
y_hat = x_i * w + b
err = y_i - y_hat
w = w + err * x
b = b + 1 * error
뉴런 클래스 구현
순전파와 역전파를 구현해준다.
먼저 순전파는 다음과 같다.
def forpass(self, x):
y_hat = x * self.w + self.b
return y_hat다음은 역전파의 구현이다.
def backprop(self, x, err):
w_grad = x * err
b_grad = 1 * err
return w_grad, b_grad훈련을 위한 fit 메소드는 다음과 같이 구현한다.
def fit(self, x, y, epochs=100):
for i in range(epochs): # 100번 훈련반복
for x_i, y_i in zip(x, y): # 모든 샘플데이터에 대해 반복
y_hat = self.forpass(x_i) # 순전파
err = -(y_i - y_hat) # 오차 계산
w_grad, b_grad = self.backprop(x_i, err) # 순전파
self.w -= w_grad # 가중치 업데이트
self.b -= b_grad # 절편 업데이트
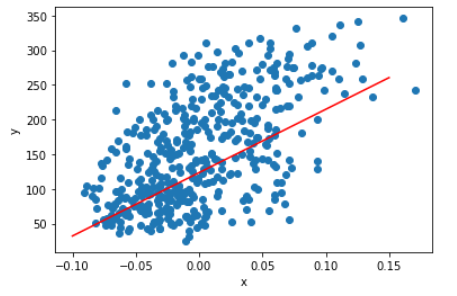
Neuron 클래스를 이용해서 훈련을 하고 모델을 그려보면 위와 같이 데이터를 잘 표현하는 것을 알 수 있다.
선형회귀는 머신러닝과 딥러닝의 근간이 되는 알고리즘이고 기본 중의 기본이므로 잘 알고있어야한다.
뿐만 아니라 linear regression과 logistic regression 같은 알고리즘은 통계학과 연관해서도 잘 알고있어야 하므로, 다음에 한번 정리해서 포스팅을 해야겠다.
//문제제기 및 피드백 언제든지 감사히 받겠습니다.
'Computer Science > DL || ML' 카테고리의 다른 글
| Data wrangling #3 - Outlier, Data Encoding (0) | 2022.06.06 |
|---|---|
| Data wrangling #2 - Data Scaling (0) | 2022.06.06 |
| Data wrangling #1 - Data Cleaning (0) | 2022.06.06 |
| [ML] KNN(k-Nearest Neighbor) (0) | 2022.05.07 |