
2022.06.06 - [Computer Science/DL || ML] - Data wrangling #1 - Data Cleaning
Data wrangling #1 - Data Cleaning
좋은 데이터사이언티스트들은 상당한 시간을 data를 cleaning 하거나 formatting 하는데 쓴다고 할 정도로 Data wrangling은 중요하다. Data wrangling 이란? Data wrangling is the process of transforming and..
faceyourfear.tistory.com
저번 시간 Data cleaning에 이어 Data wrangling의 한 종류인 Data scaling에 대해 살펴보자.
KNN 알고리즘 포스팅에서도 설명했듯이, Data scaling이란 말 그대로 data를 scaling 해주는 것이다.
Scaling이 무엇이고 왜 필요한가?
모든 feature은 단위가 다르기 때문이다.
예를 들어 우리나라 돈과 외국 돈을 비교한다고 하면, 우리나라 돈의 1200원은 미국에서는 같은 가치를 가진 돈이 1$ 이다.
그 두배인 2400원은 2$와 같다.
즉, 숫자로만 놓고 보았을 때, data의 feature에 따라 다른 값을 도출할 수도 있는 것이다.
따라서 같은 단위로 만들어주기 위해 data를 scaling 해주는 것이다.

Scaling에는 여러가지 기법이 있을 수 있지만 가장 대표적인 방법이 표준 스케일링(Standardization)이다.
scaling이 된 x_new는 원래의 값 x값들의 평균을 빼고 x값들의 표준편차를 나눠준 값이다.
Standardization을 거치게 되면 x_new의 분포는 평균이 0, 표준편차가 1인 모양이 된다.
코드를 통해 살펴보자.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(5)
n_samples = 1000
height = 4*np.random.randn(n_samples).round(2) + 170
weight = 5*np.random.randn(n_samples).round(2) + 65
df_raw = pd.DataFrame({"height": height, "weight": weight})
# copying data
df = df_raw.copy()
sns.distplot(df.height.values)키와 몸무게의 2개의 feature를 가진 dataframe을 pd_raw에 만들어준다. 그리고 df 에 df_raw를 copy 해준다.
이제 standardization을 적용해준다.
from sklearn.preprocessing import StandardScaler
scale = StandardScaler()
df[['h_sc','w_sc']] = scale.fit_transform(df[['height','weight']])
# inverse transform
# scale.inverse_transform(df[['h_sc', 'w_sc']])
# inverse transform은 표준 스케일링이 된 데이터들을 다시 원래의 값으로 되돌리는 것
sns.distplot(df.h_sc.values)사이킷런의 preprocessing에 있는 StandardScaler를 사용하여 표준스케일링을 할 수 있다.
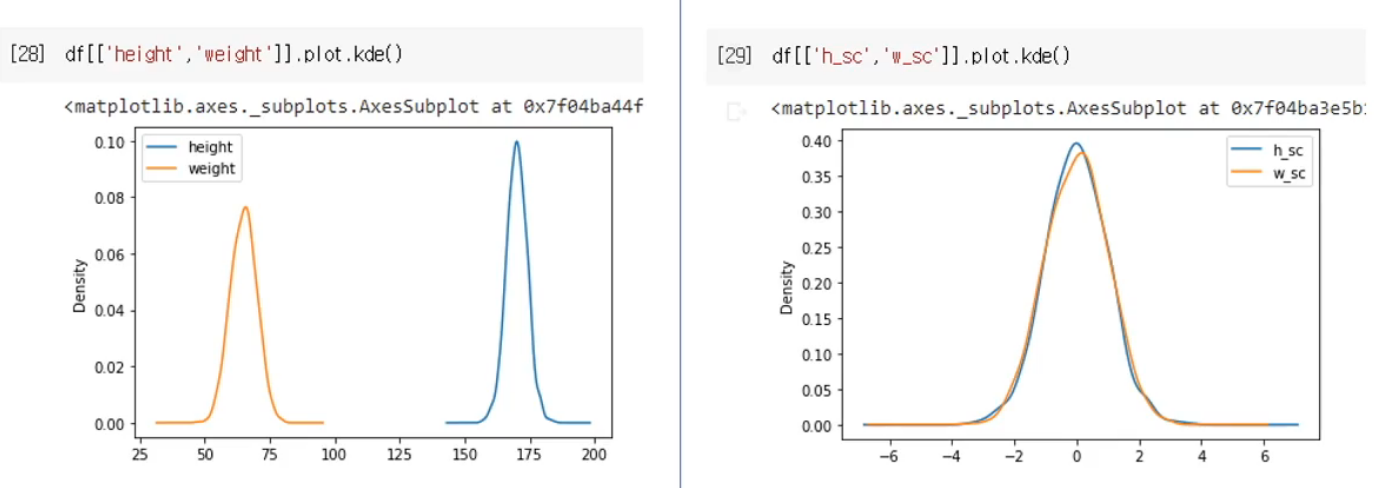
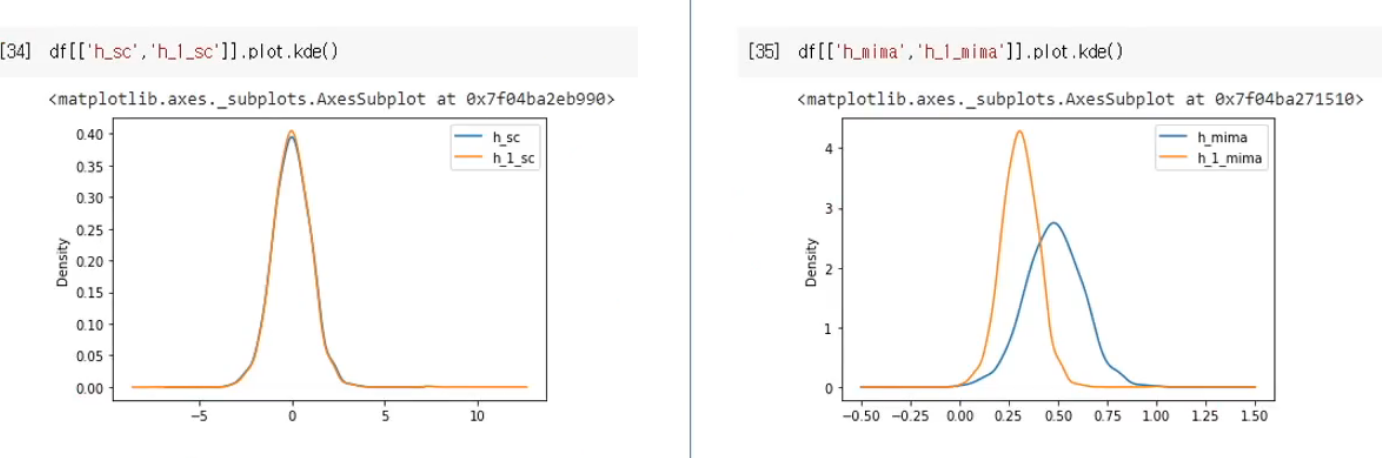
스케일링이 되기 전(좌측)과 후(우측)를 보면 왜 data scaling이 중요한 지를 알 수 있다.
다음은 min-max scaling이다.
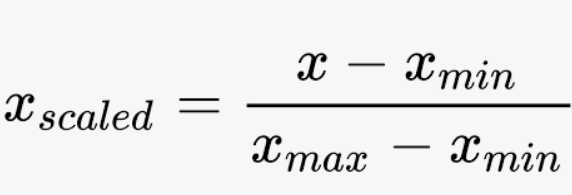
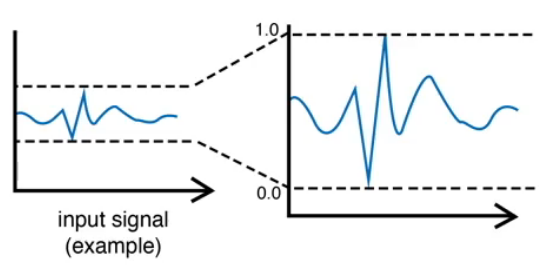
min-max scaling은 data 중 가장 큰 값에서 가장 작은 값을 뺀 max - min을 x - min 에 나눠주는 것이다.
scaling된 모든 값이 [0,1] 범위에 있게 되므로 위의 그림과 같이 signal processing 할 때 많이 적용된다.
마찬가지로 코드를 통해 자세하게 이해해보자.
from sklearn.preprocessing import MinMaxScaler
minmax = MinMaxScaler()
df[['h_mima','w_mima']] = minmax.fit_transform(df[['height','weight']])
df[["h_mima","w_mima"]].plot.kde()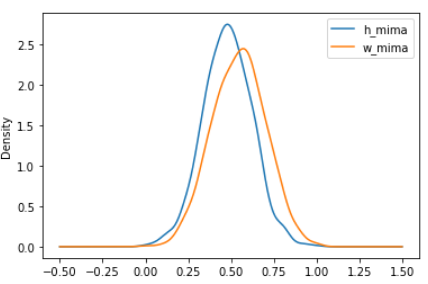
앞의 표준스케일링과 마찬가지로 사이킷런의 preprocessing에서 MinMaxScaler를 사용했다.
다만 그래프를 보니 표준스케일링과 다르게 키와 몸무게의 분포가 조금 다른 것을 확인할 수 있는데, 그 이유는 min-max scaling이 outlier(이상치)에 영향을 많이 받기 때문이다. 생각해보면 너무나 당연한 소리다.
아래의 그림을 보면
좌측은 표준스케일링, 우측은 minmax scaling인데, height의 첫번째 data의 값을 200으로 바꿔준 후 그래프를 그리니 위와 같은 결과가 나왔다.
즉 200이라는 이사이에 표준스케일링은 영향을 거의 받지 않았지만, minmax 스케일링은 영향을 크게 받은 것을 알 수 있다.
이렇게 data scaling의 두 가지 방법 Standardization과 Min-Max scaling에 대해서 알아보았다.
다음 포스팅에는 이상치를 과연 어떻게 처리해줄 것인지에 대해 알아보고, data encoding 에 대해서 알아보자.
//문제제기 및 피드백 언제든지 감사히 받겠습니다.
'Computer Science > DL || ML' 카테고리의 다른 글
| Data wrangling #3 - Outlier, Data Encoding (0) | 2022.06.06 |
|---|---|
| Data wrangling #1 - Data Cleaning (0) | 2022.06.06 |
| [ML] KNN(k-Nearest Neighbor) (0) | 2022.05.07 |
| [ML] 선형회귀(Linear Regression) (0) | 2022.04.29 |