
지난 번까지는 여러 추가적인 viewpoints 들이 얼마나 해당 scene에 대한 정보를 많이 줄 수 있는지에 대해서 알아봤었다.
Epipolar geometry는 3D scene에 대한 정보 없이 한 image plane의 점들을 다른 image plane으로 대응했었다면, 이번 강에서는 여러 2D images를 이용해서 3D scene을 recover 하는 법에 대해 알아본다.
Triangulation
Triangulation은 multiview geometry에서 가장 fundamental한 문제 중 하나다.
Triangulation은 3D point가 projection된 두 개 이상의 images를 이용해서 해당 3D point의 위치를 결정하는 작업이다.

만약 두 개의 view를 이용한 triangulation의 경우, 두 개의 camera가 있을 것이고 각각은 camera intrinsic parameter인
그리고 서로에 대한
3D 상의 점
그리고
따라서
하지만 이 방법이 수학적으로도 당연하고, 직관적이긴 하나 실제로는 잘 안 된다.
왜냐하면 real world에서는
대부분의 경우, 두 직선이 교차하지 않을 확률이 더 크므로
그렇다면 이를 어떻게 해결할 수 있을지를 고민해보자.
A linear method for triangulation
간단한 linear triangulation method를 알아보자.
두 점
Cross product의 정의에 따르면
따라서
과 같은 constraint를 얻을 수 있다.(
이 constraint들을 이용하면
이거는 이제 SVD 이용하면 된다.
이 방법이 좋은 또 다른 이유는 여러 view를 통해 얻은 여러 projection들도 그냥 행렬을 아래로 쌓기만 하면 되므로 처리하기가 쉽다.
하지만, 이 방법은 projective-invariant하지 않기 때문에 projective reconstruction에는 적합하지 않다.
예를 들어, 카메라 행렬
그러면
따라서
SVD는
따라서 이 방법은 간단하긴 하지만 대부분 optimal solution을 찾지는 못한다.
A nonlinear method for triangulation
대신 real-world에서 triangulation은 대부분 다음과 같은 minimization problem으로 표현된다.
위 식은 각
3D point의 reprojection error는 해당 점의 projection과 대응하는 점의 image plane에서의 관찰되는 point와의 distance를 의미한다.
위의 Figure2에서를 예로 들면,
따라서 image1에서의 reprojection error은
(위의 식은 모든 image의 reprojection error을 합한 것을 의미)
그렇기 때문에 더 일반화해서 식을 표현해보면
처럼 쓸 수 있다.
실제로는, 굉장히 좋은 근사치를 내는 정교한 optimization technique들이 존재하지만 이 강의에서는 이 중 하나의 기법에만 집중하기로 한다.
우리가 사용할 최적화 기법은 Gauss-Newton 알고리즘이다.
일반적인 nonlinear least squares problem의 경우는
를 minimize하는
(
이 때,
함수
하지만, image plane으로의 projection은 homogeneous coordinate으로 나눠줘야 하므로 대부분의 projection은 nonlinear하다.
따라서 카메라 행렬은 affine하지 않다.
그리고 이 식은 완벽한 nonlinear least squares problem 꼴이 된다.
그러면 어떻게 Gauss-Newton algorithm을 적용하는지 알아보자.
먼저, 앞에서 봤던 간단한 linear method로 대충 어림잡아 구한 꽤나 합리적인
Gauss-Newton algorithm은 estimate를 더 나은 방향(reprojection error을 minimize하는)으로 update 해나가는 것이다.
각 step마다 우리는
그렇다면 update parameter
Gauss-Newton 알고리즘의 key insight는 현재의 추정치인
우리의 optimization problem의 경우에는,
처럼 point
와 같이 변환된다.
이렇게 residual을 정의하면, 일반적인 linear least squares problem의 꼴과 같다.
따라서
이고 이 때
이다.
특정 이미지의 residual error vector
결과적으로 two camera의 triangulation의 경우에는 (
이 경우도 새로운 image에 대해서
이렇게 update
Gauss-Newton 알고리즘의 중요한 특성은, 우리의 estimate 근처에서 residual function이 linear 하다고 했던 가정은 수렴을 보장하지 않는다는 것이다.
따라서 정해진 update의 횟수를 정해놓고 하는 것이 실제로는 더 유용하다.
Affine structure from motion
앞 section에서는 3D scene의 정보를 얻기 위해 두 개 이상의 view를 어떻게 활용할 수 있는지 보았다. 이제는 이를 더 확장해보자.
Multiple view로부터 획득한 observations of points를 결합함으로써, **Structure from motion(SFM)**이라는 방법을 통해 해당 scene의 3D structure 뿐만 아니라 카메라의 parameter까지도 결정할 수 있다.
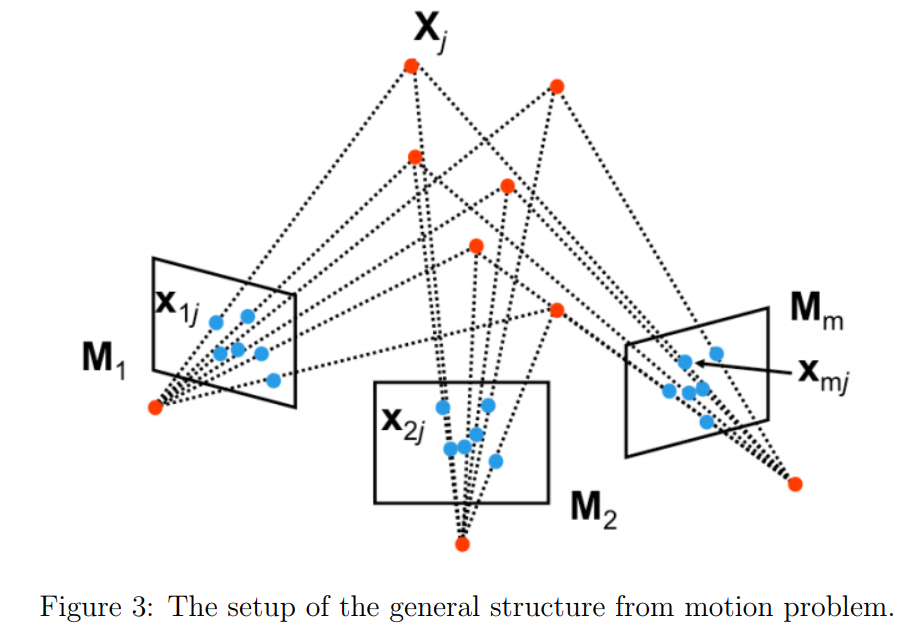
우리가
각 3D 점은 각 카메라에 location
SFM의 목적은 모든 observations
The affine structure from motion problem
General한 SFM을 다루기 전에 좀 쉬운 문제를 먼저 살펴보자.
여기서는 카메라가 affine하거나 weak-perspective임을 가정한다.
Full perspective model의 경우는
이었다. (
반면 weak perspective model의 경우
따라서 이 성질을 이용해서
과 같다. 또는 이를
와 같이 나타낼 수도 있다. (camera matrix를
SFM으로 돌아와서, 우리는
앞서 각 observation으로부터 2개의 constraint를 얻을 수 있음을 확인했었다.
따라서 총
이 식으로부터 최소 몇 개의 observation이 필요한지를 계산할 수 있는데, 예를 들어
그럼 이렇게 충분한 대응점이 있을 때, 문제를 푸는 방법에 대해 알아보자.
The Tomasi and Kanade factorization method
여기서는 Tomasi와 Kanade의 factorization method에 대해 알아본다.
이 method는 크게 두 단계로 구성된다.
- data centering step
- actual factorization step
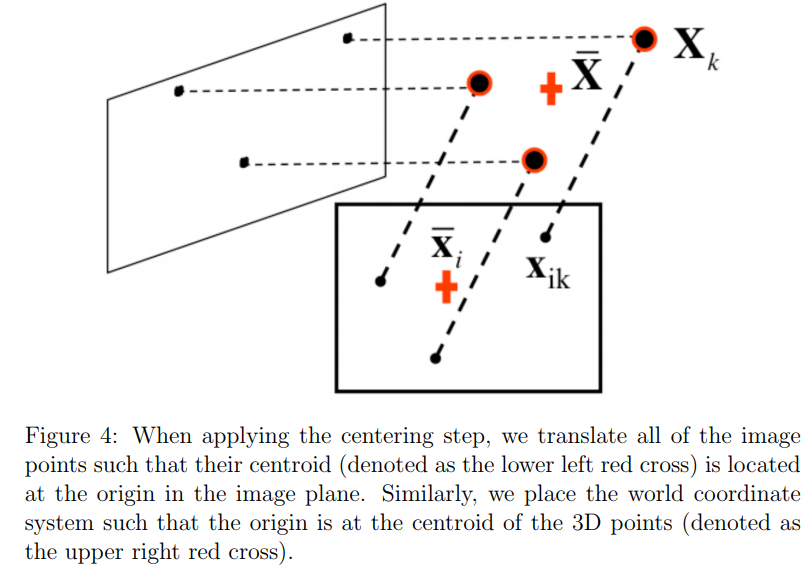
먼저 data centering step에 대해서 알아보자.
이 단계에서 main idea는 원점으로 데이터를 center시키는 것이다.
그러기 위해서 각 이미지
Affine SFM 의 경우 카메라 행렬의
과 같이 표현할 수 있다.
따라서
과 같이 유도할 수 있다.
이처럼 월드 좌표계의 원점을 centroid
궁극적으로, 이 centering step은 compact한 행렬곱으로 표현하게 해준다.
하지만,
따라서 우리는 어떻게든
모든 카메라의 모든 observation을 이용해 measurement matrix
이 된다.
Affine assumption에 따라
중요한 점은
Rank가 3인 것을 알고 있으므로, 단 3개의 non-zero singular value가
따라서 다음과 같이 분해를 할 수 있다.
하지만 실제로는 noise와 affine camera approximation에 의해 D의 rank가 3보다 크다.
하지만, rank가 3보다 클 때도,
이렇게 크기를 따져서
왜냐하면
그렇다면 뭘 골라야 할까?
Tomasi와 Kanade의 논문에서 그들은 robust한 선택은
Ambiguity in reconstruction
그럼에도 불구하고,
와 같이 invertible한 임의의 행렬
따라서 우리의 solution은 underdetermined하므로 추가적인 constraints가 필요하다.
이렇게 reconstruction이 affine ambiguity가 있다는 말은, 즉 평행성은 보존이 되고 metric scale은 알 수가 없다는 것을 의미한다.
Reconstruction에서 또 다른 중요한 ambiguity중 하나는 similarity ambiguity이다.
(rotation, translation, scaling와 같은 similarity transform에 따라 생김)
이 ambiguity는 카메라가 intrinsically calibrated 되어 있어도 존재한다.
(다행인 것은 카메라가 calibrated되어 있는 경우라면 이 ambiguity가 유일한 ambiguity임)
만약 추가적인 가정(figure에 있는 집의 높이를 안다던가)이나 추가적인 데이터를 병합하지 않는 이상 object의 scale, 정확한 위치, 표준 방향 등을 정확히 알 수는 없다.
물체를 앞뒤로 옮기는 대신 scale을 조정해주는 식으로 같은 이미지를 얻을 수 있기 때문이다.
이런 예가 바로 camera calibration이다.
Calibration을 할 때, 체커보드의 정확한 월드 좌표계에서의 위치를 알 수 있으므로 사각형의 크기에 대한 정보를 우리가 알고 있다.
따라서 우리가 metric scale을 알 수 있는 것이다.
Tomasi and Kanade factorization method 구현 코드가 궁금하다면,
https://github.com/ianpark318/CS231A/blob/main/ps2/ps2_code/PSET2.ipynb 참고
'3D\Multiview Geometry > CS231A' 카테고리의 다른 글
| CH04. Stereo Systems (2) (0) | 2023.03.05 |
|---|---|
| CH03. Epipolar Geometry (2) (0) | 2023.02.24 |
| CH03. Epipolar Geometry (1) (0) | 2023.02.12 |
| CH02. Single View Metrology (2) (0) | 2023.02.09 |
| CH02. Single View Metrology (1) (0) | 2023.02.08 |